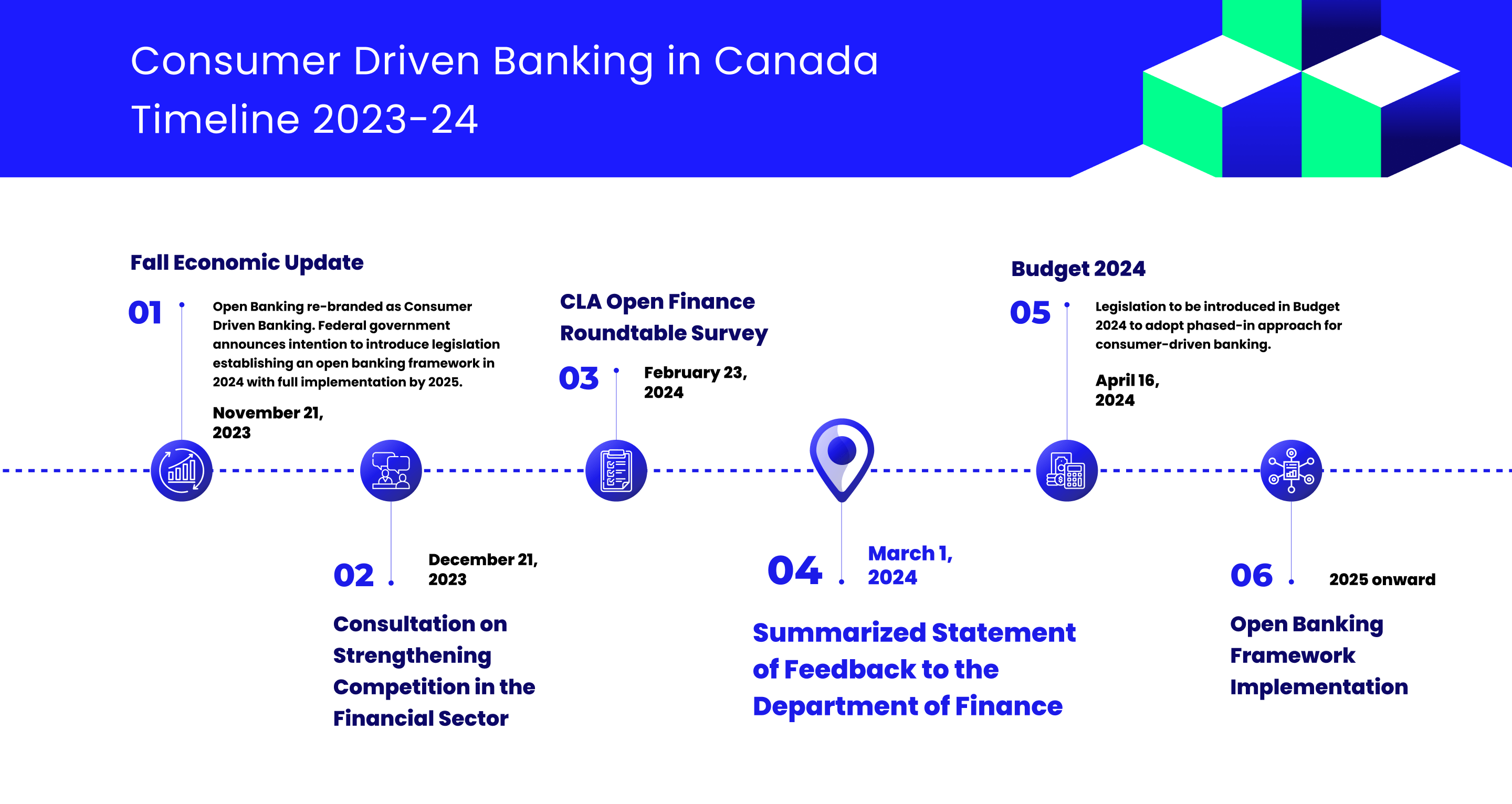
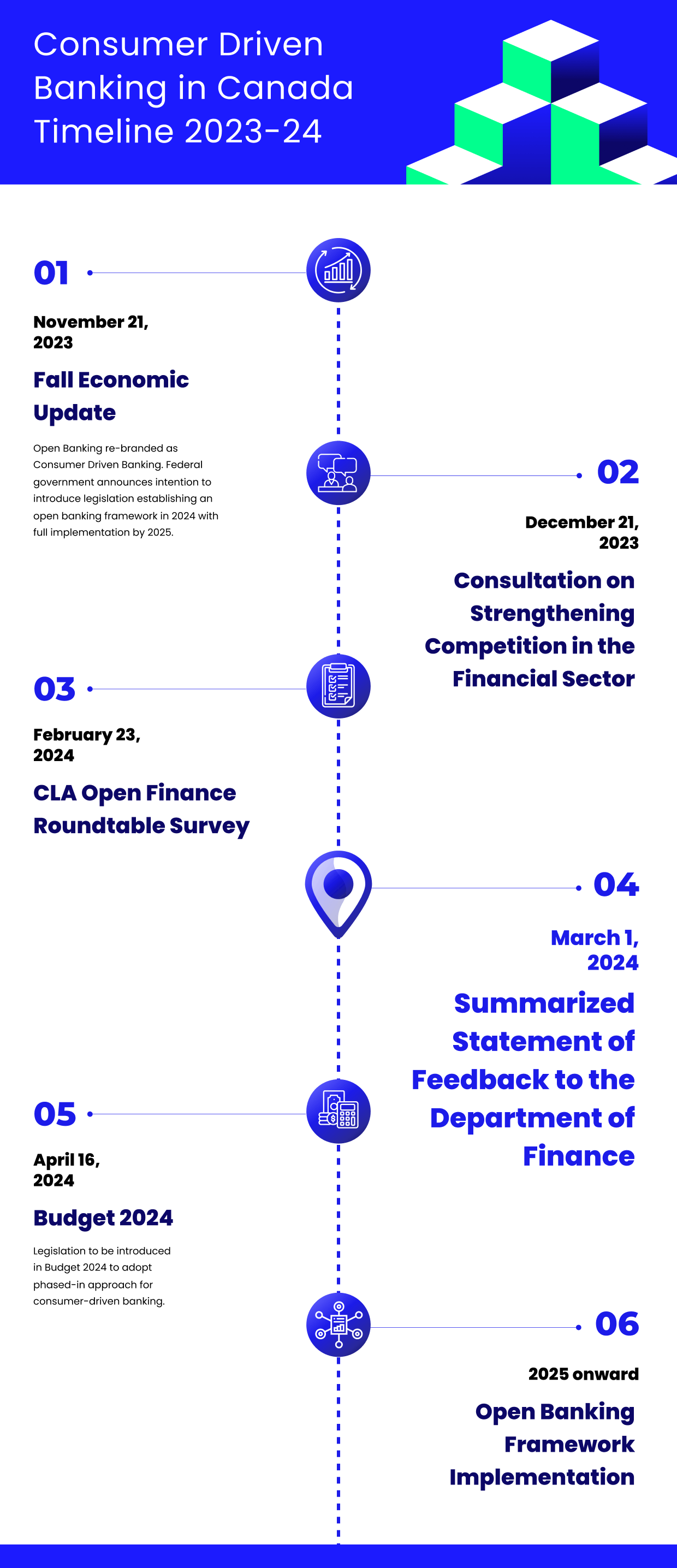
Document Processing before LLMs
Document processing primarily relies on rule-based systems and keyword matching, which can be effective for structured or even semi-structured documents with predictable formats. However, this approach often struggles with unstructured data, where variability and complexity are high. In contrast, Large Language Models (LLMs) bring a transformative approach to document understanding. They leverage advanced natural language processing (NLP) techniques, enabling them to comprehend context, semantics, and nuanced language variations in documents.
In the ever-evolving world of data science and enterprise automation, the explosive growth of unstructured data generated by companies has been a major challenge for data scientists. To give you a sense of scale, recent studies show we’re likely to witness a surge from 33 zettabytes in 2018 to a predicted 175 zettabytes by 2025. Furthermore, according to Gartner, unstructured data currently represents an estimated 80 to 90 percent of all new enterprise data. Unstructured data can include conversations through e-mail or text messages, but also social media posts, blogs, video, audio, call logs, reviews, customer feedback, and replies in questionnaires. This trend spotlights an urgent need for more sophisticated tools to create value from this burgeoning data deluge.
Our team has over 5 years working with various OCR and NLP technologies, including having developed and training models in-house. Don’t get me wrong, IDP tech has come an extremely long way and the tools have gotten tremendously powerful. Libraries such as Amazon Textract (among many others) provide ML engineers a powerful suite of tools to accelerate the speed and quality of applying intelligent document processing to automation scenarios.
However, there are still limitations to how IDP can be adopted to a range of automation scenarios that we encounter in enterprise environments.
Think of traditional models document processing tech as a diligent yet somewhat myopic librarian, meticulously following rules but often missing the bigger picture. In contrast, Large Language Models (LLMs) are like Sherlock Holmes — insightful, context-aware, omnipresent, and adept at deciphering the most cryptic of texts.
This results in several key benefits and improvements:
Enhanced Comprehension
Traditional Method: Typically relies on keyword spotting and pattern recognition. For example, extracting dates or specific terms from structured forms.
LLMs Approach: Goes beyond mere pattern recognition. It interprets language nuances and intent, essential in contexts like financial and legal document analysis where the meaning of clauses and data can be complex.
Flexibility with Unstructured Data
Traditional Method: Struggles with documents like unstructured emails or reports, often leading to high error rates or the need for manual intervention.
LLMs Approach: Excel in handling unstructured formats. For instance, in customer service, LLMs can analyze and respond to diverse customer queries that vary in structure and content, easily extract information from employment letters or mortgage commitment statements.
Dealing with unstructured data, which includes everything from casual emails to social media chatter, videos, and customer feedback, is not a trivial matter. This kind of data resists neat categorization and defies traditional database structures, posing significant challenges in analysis and comprehension. Here’s where Large Language Models show their mettle, adeptly navigating this complex, non-uniform data and unlocking valuable insights that conventional methods might miss.
Adaptive Learning
Traditional Method: Updating rule-based systems for new formats or languages is time-consuming and resource-intensive.
LLMs Approach: Can continuously learn from new data, adapting to changes in language usage or document formats without extensive manual reprogramming.
Error Reduction
Traditional Method: Prone to errors in cases of ambiguous or context-heavy information, resulting in lower reliability.
LLMs Approach: Their deep contextual understanding leads to more accurate data extraction and interpretation, crucial in high-stakes industries like legal, financial and healthcare.
A Practical Example
ChatGPT 4, without any specific fine tuning or pre-training is able to easily extract information from a document it has never seen before. It understands the context and you can simply query in a natural way for data points that you are interested in:
*
* Note: we take data privacy and PII seriously (see below) and created “spoof” documents for the purposes of this demonstration.
For instance, by asking direct questions such as ‘What is the policy end date?’ or ‘By what margin has the insured amount varied?’, it promptly delivers precise information with perfect accuracy.

This scenario offers the opportunity to further explore solutions that leverage the unique capabilities of LLM’s for the purposes of intelligent document processing and automation.
Generative AI-Powered Extraction and Comparison of Insurance Policy Documents
In the previous section, we delved into the capabilities of Language Learning Models (LLMs) in streamlining the extraction of key information from various document types. To demonstrate this further, we now present a practical application of our system.
The first part of the demonstration involves uploading the initial insurance policy, which acts as our benchmark document. Watch how the system seamlessly processes this document, effortlessly extracting critical details such as the policy number, coverage specifics, the insured party’s information, and other essential data.
Next, we upload a second document representing a modification in the policy. It not only extracts pertinent information from the new document but also conducts an intelligent comparison with the original policy. Notice how the system highlights the changes in the date and insurance limit. This comparative analysis is vital to ensure comprehensive and accurate updates of all modifications and their implications.
To enhance the efficiency of such systems, integration with existing databases and cloud storage services is key. Utilizing APIs, these systems can automatically retrieve documents from various sources such as cloud storage (like AWS S3, Google Cloud Storage), internal databases, or even directly from email attachments. This integration enables real-time processing and updates, ensuring that the latest documents are always analyzed and compared.
The Role of Retrieval-Augmented Generation (RAG) in LLMs
For more context specific answers and solutions, Retrieval-Augmented Generation represents a significant advancement in the capabilities of LLMs. It’s another step forward on this never-ending roller coaster!
- Enhanced Accuracy and Relevance: RAG combines the generative power of LLMs with information retrieval, pulling in relevant data or documents to provide contextually accurate responses. This is particularly beneficial for financial analysis and reporting, where accuracy is paramount.
- Dynamic Data Integration: Unlike traditional LLMs, RAG can integrate real-time data, offering dynamic responses to financial queries. This is essential in finance, where market conditions and regulatory environments are constantly evolving.
- Customized Financial Advice: RAG’s ability to retrieve and process vast amounts of data allows for highly personalized financial advice, tailored to individual customer profiles and market conditions.
- Improved Compliance and Risk Management: In the regulatory-heavy landscape of financial services and healthcare industries, RAG can efficiently process and cross-reference internal and external data sources including detailed regulations and requirements. We believe that there is a huge opportunity to automate regulatory, risk, and compliance checklists to reduce complex manual efforts that exist in regulated industries.
Potential limitations of deploying LLM’s for document processing (at scale)
While LLMs are highly likely to revolutionize document processing with, it is important to consider potential limitations as well. LLMs are like a double-edged sword, powerful in processing vast amounts of data but requiring careful handling to address privacy concerns and manage computing resources.
- Privacy and Personal Identifiable Information (PII): LLMs are capable of processing vast amounts of data, including confidential or proprietary information as well as PII data. Organizations must work within data security frameworks and engineer solutions that have data security at the core of how they are designed and deployed. As a SOC2 Certified company, this is an area of key focus for our teams and we have implemented robust data handling and processing protocols to ensure that all PII is managed securely and in compliance with privacy regulations.
- Computing Power and Cost: The potential impact offered by powerful LLMs to read and extract data from large volumes of unstructured data is reliant on the on substantial computing power required to run these models. We are still in the early stages of enterprise adoption of generative AI technologies and the economics of leveraging these toolsets at an enterprise scale are fairly dynamic. We expect a lot to change over the next few years but in the meantime, we are actively working with clients to understand the business drivers of using LLM’s to automate processes. With our deep background in intelligent document processing we’ve become experts at crafting solutions that optimize model efficiency without compromising performance. We employ techniques like model pruning, efficient data processing pipelines, and cloud-based solutions that balance computational demands with cost-effectiveness.
Conclusion
LLMs and RAG are the vibrant threads bringing new patterns of efficiency, accuracy, and innovation. We’ve journeyed from the meticulous yet narrow pathways of traditional methods to the expansive highways of AI-driven solutions. This evolution isn’t just a step forward; it’s a quantum leap into a future where data isn’t just processed but understood, where advice isn’t just given but tailored, and where compliance isn’t just followed but mastered.
The advancements in unstructured data analytics signal a critical shift in our approach to data. It’s not just about the volume; it’s about the untapped potential that lies within. This raises a compelling question: how can we leverage unstructured data to gain a deeper understanding of our customers, societal trends, and the world at large? The key lies in harmonizing cutting-edge AI tools like Large Language Models with human insight, transforming this wave of data into insightful and actionable knowledge.